In this tutorial, we are going to show how to easily index NFT Metadata by
leveraging a serverless job queue like Inngest.
Implementing a robust and scalable NFT metadata indexer is hard, your indexer
needs to take the following into consideration:
- you need to "discover" NFT tokens by listening to onchain activity.
- fetching the NFT token URL is slow because it involves a JSON-RPC call.
- the NFT metadata server may be temporarily or permanently unavailable.
- you need to take into account rate limits for both the JSON-RPC server
and the metadata servers.
- you want to concurrently fetch the metadata for as many tokens as possible
to speed up indexing.
Luckily, all of the issues above are solved by using modern developers tools
like Apibara and Inngest.
Apibara is an open-source platform to build indexers. Our philosophy is to focus
on streaming and transforming data and then sending the result to third-party
integrations. In this case, we use Apibara to trigger jobs in a task queue.
Inngest is a serverless task queue: you start by implementing durable tasks using
Javascript or Typescript. Durable tasks are functions composed by one or more
steps (for example, fetch the token URL, or fetch metadata). Inngest will run
each step in order, automatically retrying a step if it fails. With Inngest, you
can implement complex workflows without having to worry about scheduling or
retries.
In the next sections, you will learn how to:
Before we begin, you should visit the getting started guide to learn how to
install and configure Apibara.
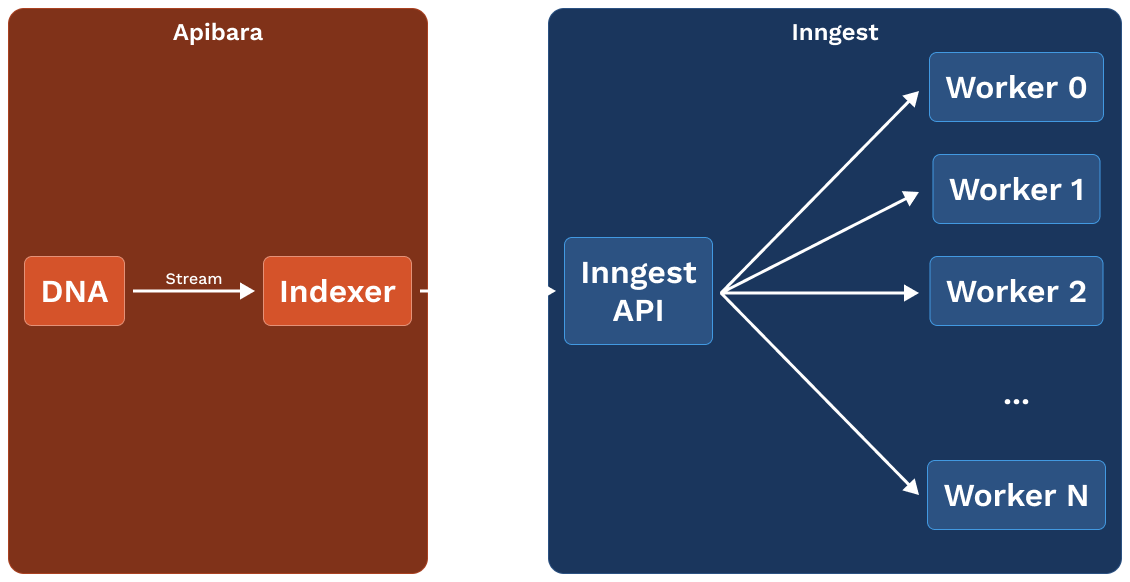
The image below contains the reference architecture of what we are going to
build in this tutorial:
- an indexer streams data from a DNA server.
- the indexer uses onchain data to determine which NFT needs indexing and
invokes a new Inngest task.
- Inngest schedules workers to index the NFT metadata.
As always, the source code for this tutorial is available on
GitHub.
Setting up Deno & Inngest
For this tutorial, we are going to use Deno as the Javascript runtime. Refer to
this guide to setup Deno on your
machine. Note that you
can follow along this tutorial using Node.js if you prefer that.
We start by creating a src/inngest folder to contain all Inngest-related code.
We create a file src/inngest/client.ts that contains the definition for our
Inngest client. It contains the schema for the events that will trigger our
tasks and the Inngest client. Notice that since we are running Inngest locally,
we use the "local" eventKey.
import { EventSchemas, Inngest } from "https://esm.sh/inngest";
type Events = {
"nft/mint": {
data: {
address: string;
tokenId: string;
};
};
}
export const inngest = new Inngest({
name: "NFT Metadata Tutorial",
eventKey: "local",
schemas: new EventSchemas().fromRecord<Events>(),
});
The next step is to create a file containing the definition of the task we want
to run. We do that in src/inngest/fetch_metadata.ts. You can learn more about
writing Inngest functions in the official
documentation.
import { inngest } from "./client.ts";
export const fetchMetadata = inngest.createFunction(
{ name: "fetchMetadata" },
{ event: "nft/mint" },
async ({ event, step }) => {
// ⚡ Use `step.run` to asynchronously run a that may fail. Inngest will
// automatically retry it if it fails.
const metadataUrl = await step.run("Fetch token URL", () => {
// Here we could fetch the metadata URL from the node using an RPC call.
return `https://cloud.argent-api.com/v1/moments/metadata/1/${event.data.tokenId}`
});
const metadata = await step.run("Fetch metadata", async () => {
const response = await fetch(metadataUrl);
return await response.json();
});
return {
event,
body: metadata,
}
},
);
The last step is to create the HTTP server that we will use later to start new
tasks. In this case we use express, but you can integrate with other frameworks
such as Next.js. We implement the server in src/server.ts:
import express from "https://esm.sh/express";
import { serve } from "https://esm.sh/inngest/express";
import { inngest } from "./inngest/client.ts";
import { fetchMetadata } from "./inngest/fetch_metadata.ts";
const app = express();
// @ts-ignore - express types are wrong
app.use(express.json());
app.use("/api/inngest", serve(inngest, [fetchMetadata]));
app.get("/health", (_req, res) => {
res.send("OK");
});
app.listen(8000, () => {
console.log("Started server on port 8000");
});
Starting Inngest
We are now ready to start the Inngest server. From the root of your project, run
deno run --allow-all src/server.ts to start the express server. In another
terminal, start the Inngest UI with npx inngest-cli@latest dev -u http://localhost:8000/api/inngest and then visit http://127.0.0.1:8288.
If you navigate to the "Apps" section, you should see the application we defined
in src/inngest/client.ts.
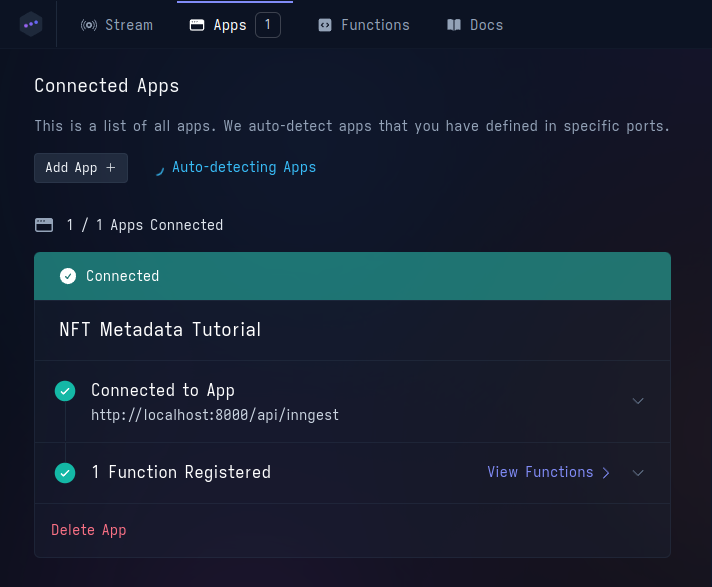
We are now ready to invoke Inngest functions using Apibara.
Trigger functions with Apibara
We are going to write an Apibara indexer to invoke Inngest functions. Inngest
provides an HTTP endpoint where we can send events (like the nft/mint we defined)
to start the function to fetch metadata we defined previously.
We are going to use the Webhook integration to invoke this endpoint for each
NFT minted.
For this tutorial, we are going to use the "Argent: Xplorer" collection as an
example, but you can use the same strategy on any NFT collection.
We are going to create a src/indexer.ts file. This file contains the indexer
configuration and a transform function (more on this later).
We configure the indexer to receive Transfer events from the 0x01b2...3066
smart contract, starting at block 54 900 (when the contract was deployed).
Finally, we configure the sink. In this case we want to use the webhook sink
to send the data returned by the transform function to the HTTP endpoint
specified in the configuration. We turn on the raw option to send data to the
endpoint exactly as it's returned by the transform function.
import { hash, uint256 } from "https://esm.sh/starknet";
import type { Config } from "https://esm.sh/@apibara/indexer";
import type { Starknet, Block, BlockHeader, EventWithTransaction } from "https://esm.sh/@apibara/indexer/starknet";
import type { Webhook } from "https://esm.sh/@apibara/indexer/sink/webhook";
export const config: Config<Starknet, Webhook> = {
streamUrl: "https://mainnet.starknet.a5a.ch",
startingBlock: 54_900,
network: "starknet",
filter: {
header: {
weak: true,
},
events: [
{
fromAddress: "0x01b22f7a9d18754c994ae0ee9adb4628d414232e3ebd748c386ac286f86c3066",
keys: [hash.getSelectorFromName("Transfer")]
},
],
},
sinkType: "webhook",
sinkOptions: {
targetUrl: "http://localhost:8288/e/env_key",
raw: true,
},
};
As we mentioned early, Apibara uses the transform function exported by the
script to transform each Starknet block into a piece of data that is specific to
your application. In this case, we want to perform the following:
Note that we can schedule multiple tasks by sending a list of event payloads.
Add the following code at the end of src/indexer.ts. Since an Apibara indexer
is just regular Typescript, you can continue using any library you already use
and share code with your frontend.
export default function transform({ header, events }: Block) {
return events.flatMap((event) => transferToTask(header!, event));
}
function transferToTask(_header: BlockHeader, { event }: EventWithTransaction) {
const from = BigInt(event.data[0]);
if (from !== 0n) {
return [];
}
const tokenId = uint256.uint256ToBN({
low: event.data[2],
high: event.data[3]
}).toString();
return [{
name: "nft/mint",
data: {
address: event.fromAddress,
tokenId,
},
}];
}
Now you can run the indexer with apibara run src/indexer.ts -A <dna-token>,
where <dna-token> is your Apibara DNA authentication token (you can create one
in the Apibara dashboard). You will see your indexer going through Starknet
events block by block and pushing new tasks to Inngest.
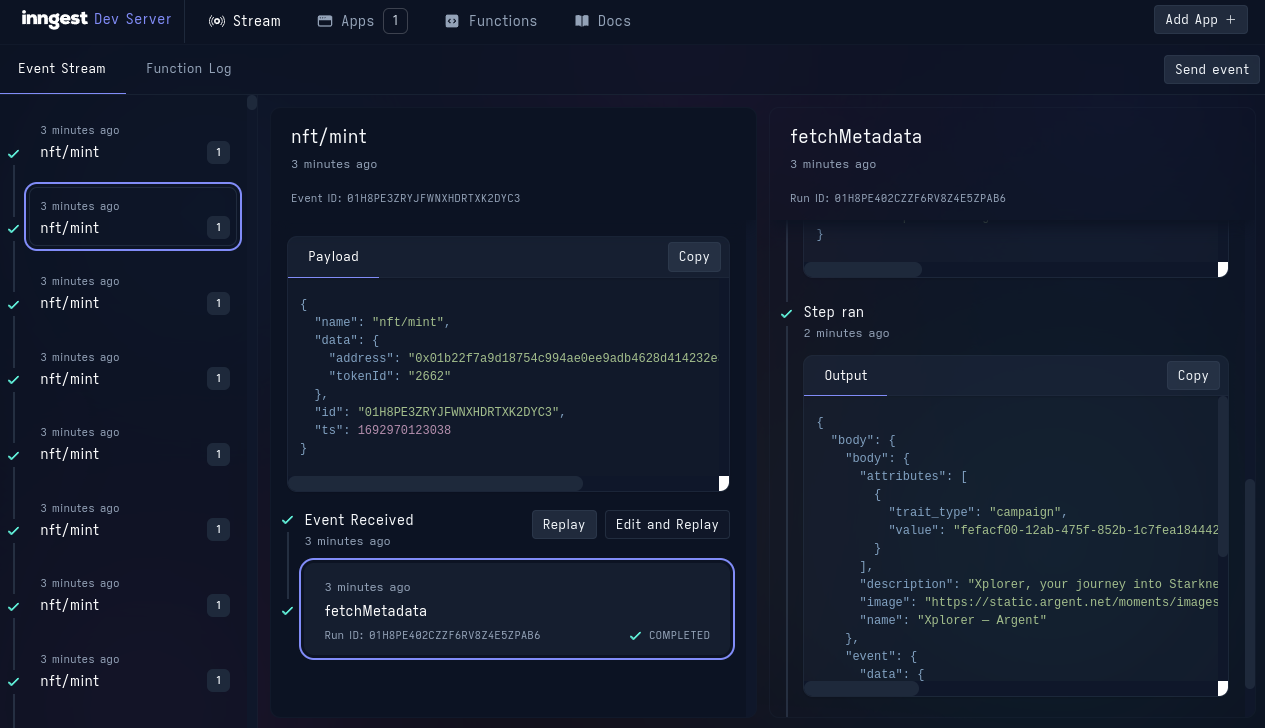
You can see all function invocations in the Inngest UI. Select one event to see
the function steps in real-time, together with their return values.
What's next
This tutorial showed how to get started integrating Inngest with Apibara. If you
want to take this tutorial further and use it for your project, you can explore
the following possibilities: